Abstract
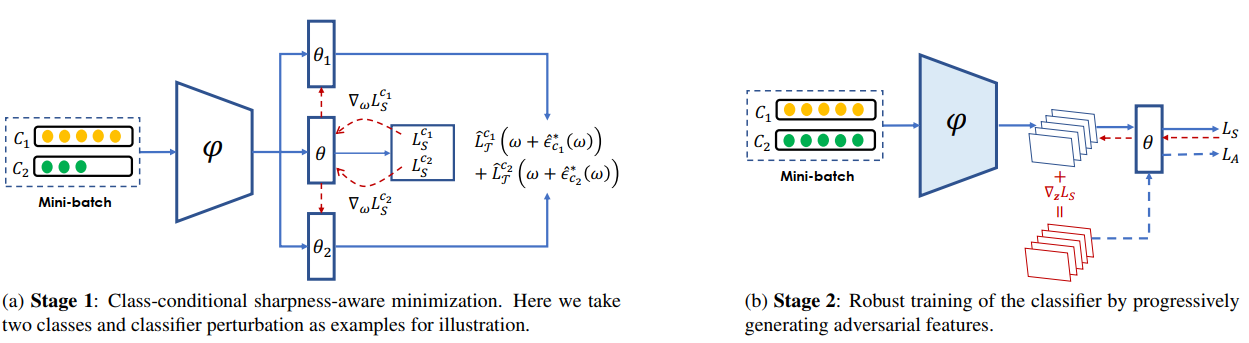
It’s widely acknowledged that deep learning models with flatter minima in its loss landscape tend to generalize better. However, such property is under-explored in deep long-tailed recognition (DLTR), a practical problem where the model is required to generalize equally well across all classes when trained on highly imbalanced label distribution. In this paper, through empirical observations, we argue that sharp minima are in fact prevalent in deep longtailed models, whereas na¨ıve integration of existing flattening operations into long-tailed learning algorithms brings little improvement. Instead, we propose an effective twostage sharpness-aware optimization approach based on the decoupling paradigm in DLTR. In the first stage, both the feature extractor and classifier are trained under parameter perturbations at a class-conditioned scale, which is theoretically motivated by the characteristic radius of flat minima under the PAC-Bayesian framework. In the second stage, we generate adversarial features with classbalanced sampling to further robustify the classifier with the backbone frozen. Extensive experiments on multiple longtailed visual recognition benchmarks show that, our proposed Class-Conditional Sharpness-Aware Minimization (CC-SAM), achieves competitive performance compared to the state-of-the-arts.
Author
Zhipeng Zhou,Lanqing Li, Peilin Zhao, Pheng-Ann Heng, Wei Gong.
Publication
IEEE/CVF CVPR (CCF-A)
Keywords
Deep Long-Tailed Recognition, Sharpness Aware Minimization