实验室最新成果Sparse Mixture of Experts Language Models Excel in Knowledge Distillation发表在NLPCC会议上。该研究介绍了MoE-KD,一种从密集模型向更强的稀疏专家混合模型进行蒸馏的方法。
在利用知识蒸馏减少语言模型参数数量的同时,研究人员还通过改进损失函数和训练技术解决了性能损失问题。例如,一些研究采用 f-散度函数或反向Kullback-Leibler散度(KLD)来优化通常使用的正向KLD损失函数。这使得学生模型能够更好地捕捉教师模型的分布,并增强了其生成能力。此外,还有一些研究通过强化学习和对学生模型生成输出的训练来优化知识蒸馏的训练过程。
这些蒸馏技术通过改进损失函数和训练方法提高了模型蒸馏的有效性。然而,它们很少关注学生模型结构的优化,通常是从密集的教师模型蒸馏到相同架构的密集学生模型。在以前的方法中,改变学生模型的结构或使用更强的架构很少被考虑。一方面,更改模型结构需要继续预训练,这需要相当于数百次微调的计算资源。另一方面,将知识蒸馏到具有不同结构的更强预训练模型中会遇到与分词器相关的困难。
受到专家混合模型(Mixture of Experts, MoE)优异性能的启发,我们提出了一种从密集模型向更强的稀疏专家混合模型进行蒸馏的方法,以缩小学生模型与教师模型之间的能力差距,从而提升模型性能。基于前人的工作,我们设计了一种低秩专家混合模型结构,这种结构在不需要额外预训练的情况下加强了学生模型的能力。我们在三个任务无关的数据集和三个任务相关的数据集上进行了实验。实验结果表明,我们的方法,即MoE-KD,在五个任务上的表现优于向密集学生模型进行蒸馏的方法。
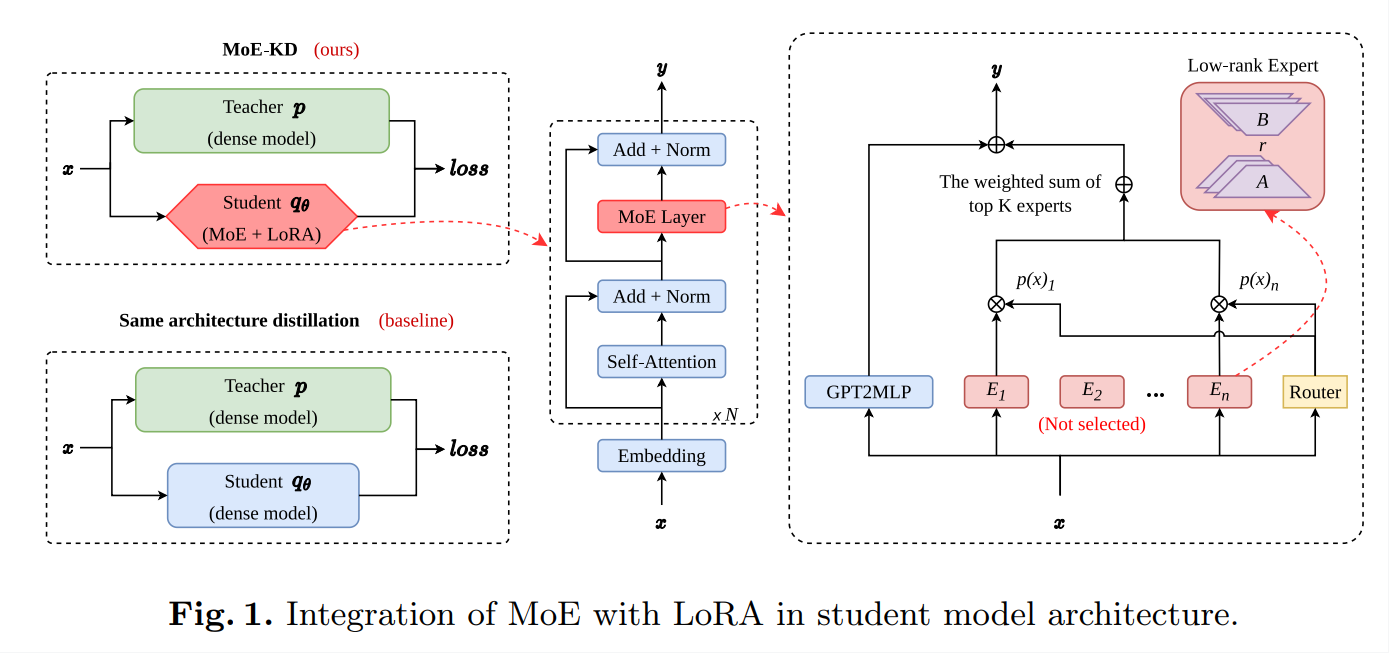
Fig. 1. Integration of MoE with LoRA in student model architecture
我们的贡献在于将MoE与LoRA结合,以增强在各种任务中知识蒸馏的有效性。此外,我们的方法天然兼容其他蒸馏技术。通过这种方式,我们不仅提高了模型的性能,还减少了计算资源的需求,使大型语言模型能够在更多的实际应用场景中得以部署和使用。
这项研究为解决大型语言模型的计算瓶颈提供了新的思路,同时也为未来的模型优化和应用开辟了新的可能性。通过引入MoE结构和有效的蒸馏技术,我们展示了如何在保持甚至提升模型性能的同时,减少计算消耗,这对于推动自然语言处理技术在实际应用中的普及和发展具有重要意义。未来的工作可以进一步探索如何在更多复杂的任务中应用这一方法,并研究如何优化MoE结构以适应更多样的应用场景。
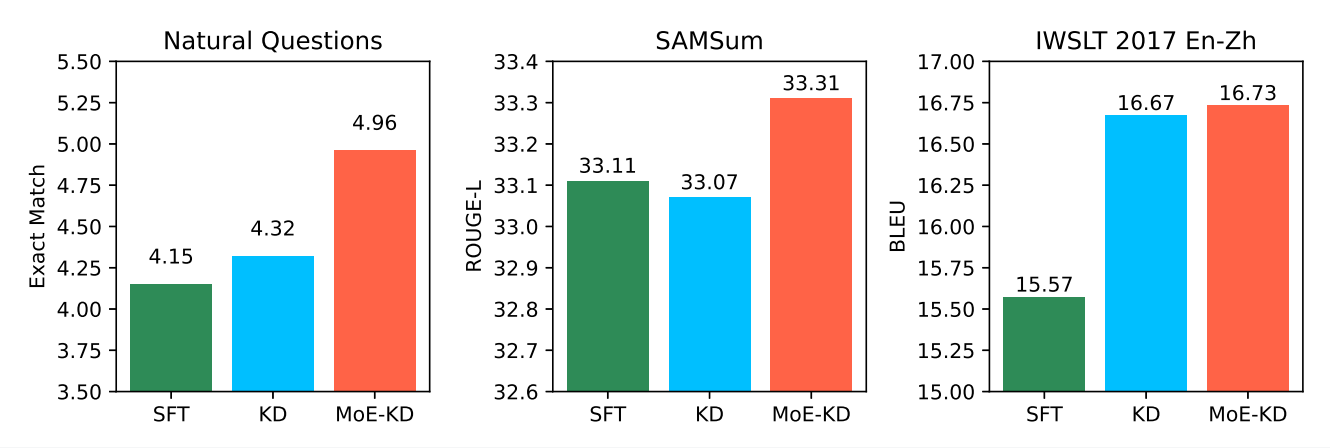
Fig. 2. Comparison of model performance on three task-specific data
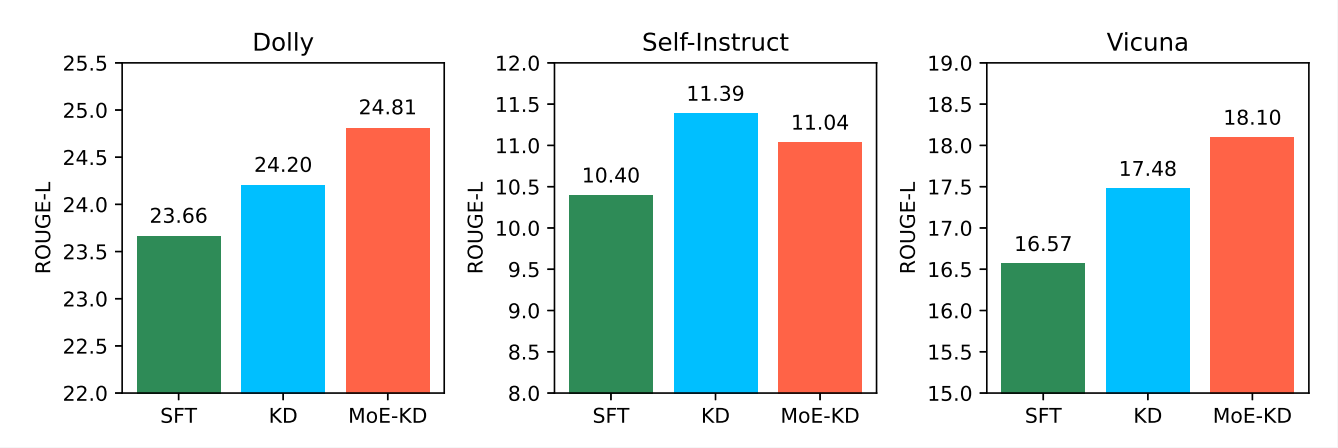
Fig. 3. Comparison of model performance on three task-agnostic datasets
本研究第一作者徐海洋是中国科学技术大学人工智能与数据科学学院硕士研究生,通讯作者龚伟是中国科学技术大学计算机科学与技术学院教授。
论文链接:https://openreview.net/forum?id=PhJnMNETzv#discussion