面向医疗安全关键决策的离线逆向约束强化学习
摘要
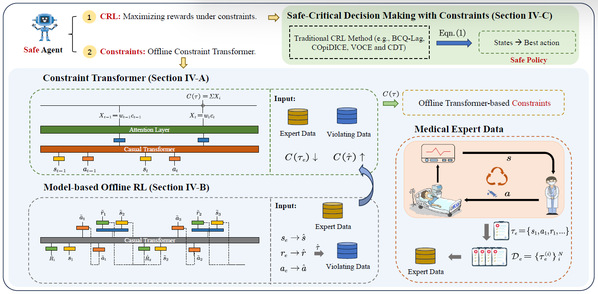
强化学习(RL)在医疗健康领域的一个重要应用是优化治疗决策。然而,原始的RL策略可能导致不安全的医疗决策,例如过量用药或治疗方案的突然改变,这通常是因为智能体未能考虑常识性约束。为了缓解这些问题,约束强化学习(CRL)通过预定义约束条件优化策略,自然成为一种实现更安全决策的有前景方法。将CRL扩展到医疗应用时,一个核心挑战在于如何为不同医疗场景准确设定约束函数。近期出现的逆向约束强化学习(ICRL)是一种从专家示范中推断约束的有效方法。然而,ICRL算法建模的是马尔可夫决策过程,并依赖实时交互环境。这些设定与医疗决策系统的实际需求不符,因为医疗决策依赖于离线数据集中记录的历史治疗信息。针对这些问题,我们提出约束变换器(CT)。具体而言:1)我们采用因果注意力机制将历史决策和观测数据融入约束建模,同时使用非马尔可夫层对加权约束进行关键状态捕捉;2)通过生成式世界模型进行探索性数据增强,使离线RL方法能够模拟不安全决策序列。在多种医疗场景中的实证结果表明,CT能有效识别不安全状态,获得接近更低死亡率的策略,并降低不安全行为的发生概率。
作者
方楠,刘桂良,龚伟
期刊\会议
IEEE Transactions on Artificial Intelligence [Link]
关键词
人工智能;医疗保健;医疗服务,安全强化学习