The latest results of the laboratory: Spas, Miks, Turben, Expertzland, Guagmoders, Axel, Innolic, Disti, Latian, presented at the Empke conference. The study introduces Mo-Kerd, a method for distilling from a dense model to a stronger sparse expert hybrid model.
Current auto-regressive large language models have achieved significant success across various domains. However, their computational and memory requirements are substantial, which hinders the deployment of these models in practical scenarios. To mitigate the computational consumption of large language models, researchers have proposed numerous methods, among which knowledge distillation stands out as a key technique. It compresses insights from a large teacher model into a smaller student model, thereby reducing computational costs.
While leveraging knowledge distillation to decrease the number of parameters in language models, researchers have also addressed the performance loss issue by improving loss functions and training techniques. For instance, have employed the f-divergence function or reverse Kullback-Leibler divergence (KLD) to refine the commonly used forward KLD loss in distillation. This allows the student model to better capture the distribution of the teacher model and enhances its generative capabilities. Moreover, have optimized the training process of knowledge distillation using reinforcement learning and training on outputs generated by the student model.
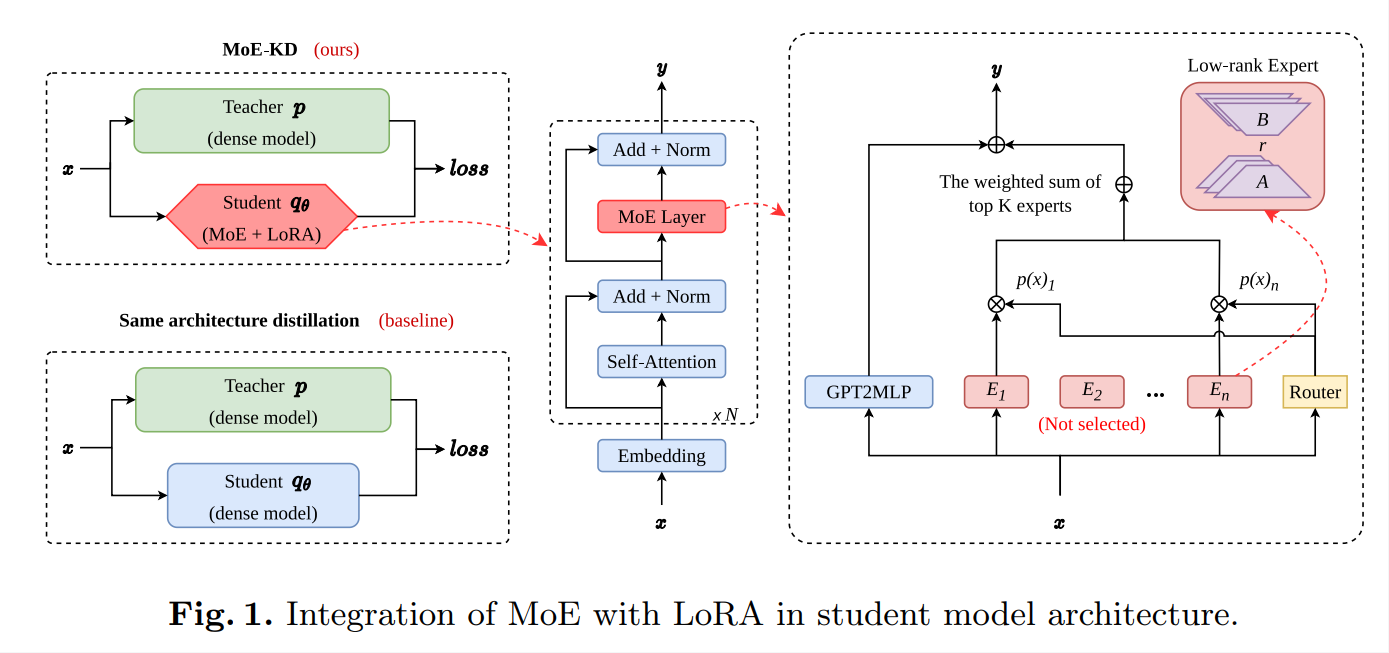
Fig. 1. Integration of MoE with LoRA in student model architecture
These distillation techniques have improved the effectiveness of model distillation by refining loss functions and training methods. However, they seldom focus on optimizing the structure of the student model, typically distilling from a dense teacher model to a dense student model of the same architecture. In previous approaches, altering the student model's structure or using a stronger architecture is rarely considered. On the one hand, changing the model structure necessitates continued pretraining, which requires computational resources equivalent to hundreds of times of fine-tuning. Moreover, it is challenging to determine which structural modifications are more effective. On the other hand, distilling to a stronger pre-trained model with a different structure encounters difficulties with the tokenizer.
Inspired by the exceptional performance of mixture-of-experts models, we propose distilling from a dense model to a stronger sparse mixture-of-experts model to reduce the capability gap between the student and teacher models, thereby enhancing model performance. Building upon the work of , we have designed the low-rank mixture-of-experts model structure, which strengthens the student's capabilities without continued pretraining. We conducted experiments on three task-agnostic and three task-specific datasets. The results indicate that our method, termed MoE-KD, outperforms distillation to dense student models on five tasks.
Our contribution involves combining MoE with LoRA to enhance the effectiveness of knowledge distillation across various tasks. Moreover, our method is naturally compatible with other distillation techniques.
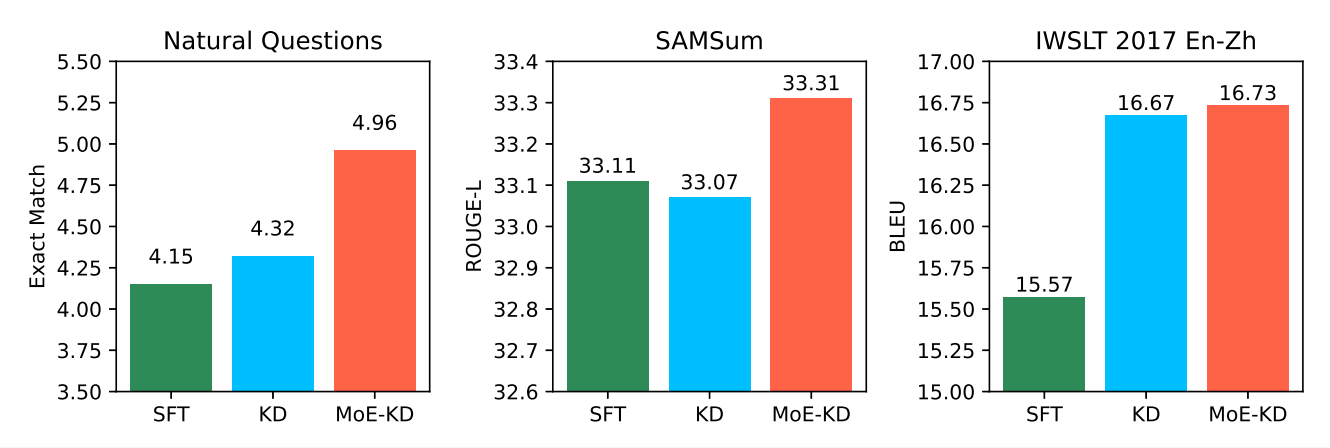
Fig. 2. Comparison of model performance on three task-specific data
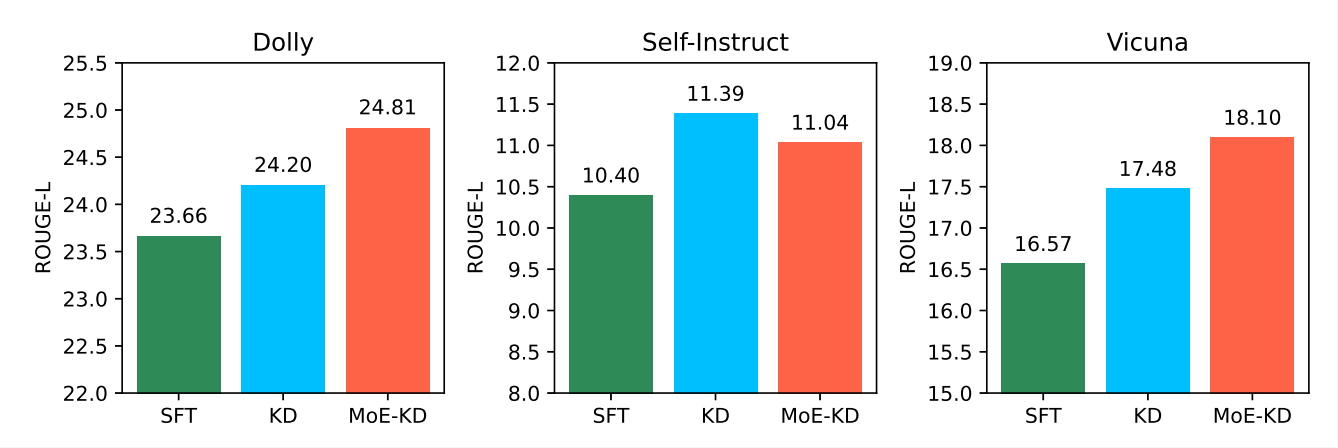
Fig. 3. Comparison of model performance on three task-agnostic datasets
Haiyang xv, is a master candidate in the School of Artificial Intelligence and Data Science, University of Science and Technology of China, and the corresponding author, Wei Gong, is a professor in the School of Computer Science and Technology, University of Science and Technology of China.
Link:https://openreview.net/forum?id=PhJnMNETzv#discussion